

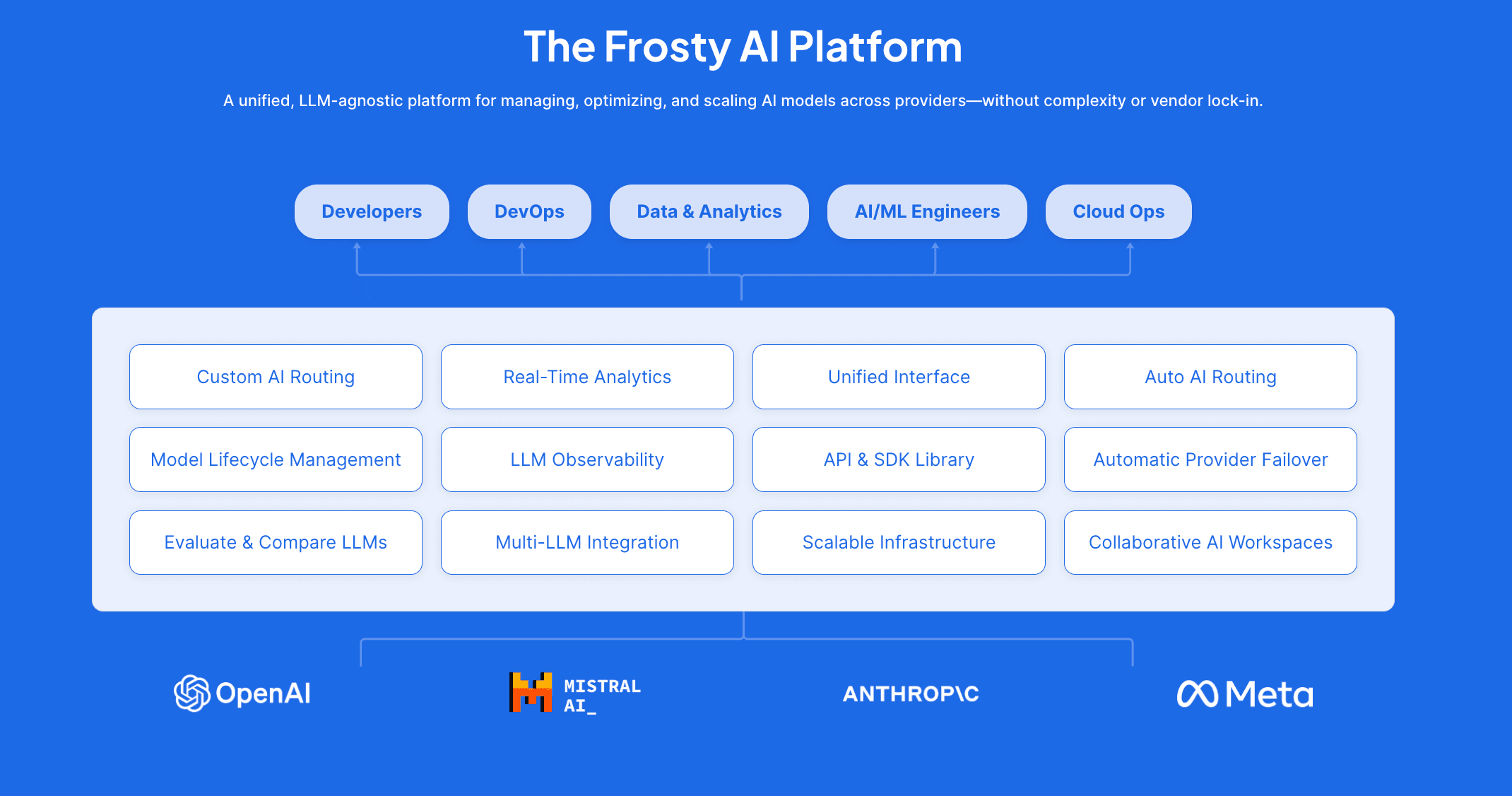
How Frosty AI Helps You Scale Your AI Environment Without the Complexity
The Challenges of AI Model Management
The rise of Large Language Models has unlocked massive potential for businesses across industries. However, as organizations experiment with multiple AI providers, they encounter significant challenges that slow innovation, drive up costs, and create inefficiencies.
1. Vendor Lock-In Limits Flexibility
Most companies start with a single AI provider like OpenAI or Anthropic. But as their AI needs evolve, they quickly realize:
Some tasks require cheaper models, while others need higher accuracy.
Vendor outages can disrupt mission-critical workflows.
Switching providers requires code changes, adding development overhead.
💡 Companies get locked into a single provider, limiting their ability to adapt to new models and pricing changes.
2. Unpredictable Costs Make AI Budgets Unmanageable
AI models are expensive, and costs are difficult to predict. Companies face:
Hidden pricing differences between providers.
Surprise overages when token usage spikes.
No real-time cost controls, leading to budget overruns.
💡 Without an efficient way to route queries to cost-effective models, companies overpay for AI without seeing better results.
3. Lack of Observability Leads to Poor AI Performance
Most teams don’t have visibility into how their AI models are performing. They struggle to answer:
Which models perform best for specific use cases?
How often do models fail, and what’s the impact on users?
What’s the latency and response time across different models?
💡 AI teams lack the observability they need to fine-tune performance, debug failures, and optimize response times.
4. Failover is Nonexistent—And Outages Are Costly
If an AI provider goes down, most companies have no backup plan. This results in:
Service disruptions for customer-facing AI products.
Lost revenue and frustrated users.
High engineering costs to build a manual failover system.
💡 AI should be as reliable as cloud infrastructure—yet most teams are stilling designing failover strategy in place.
5. Scaling AI Across Teams is Chaotic
As AI adoption grows within an organization, different teams start using different models without coordination. This leads to:
Fragmented AI strategies, where different teams use different models without a unified approach.
Inconsistent performance, as teams lack clear guidelines on when to use which model.
Massive inefficiencies, with redundant costs, duplication of efforts, and no shared learnings.
💡 AI teams need a standardized, scalable framework to manage AI adoption across the company.
The Solution: How Frosty AI Fixes These Problems
At Frosty AI, we’ve built a LLM-agnostic AI platform to help companies take back control of their AI workflows.
✅ Eliminate Vendor Lock-In – Route queries to any LLM provider (OpenAI, Anthropic, Mistral, etc.) without changing your code.
✅ Optimize Costs in Real-Time – Automatically choose the most cost-effective model based on pricing and usage.
✅ Gain Full Observability – Get detailed analytics, logging, and performance insights across all AI models.
✅ Ensure 100% Uptime – Enable automatic failover, so if a model goes down, Frosty seamlessly switches to another provider.
✅ Standardize AI Scaling Across Teams – Use a simple AI adoption framework that ensures every team follows best practices.
The Frosty AI Scaling Framework: A Simple System for AI Growth
To avoid chaos and ensure efficient AI scaling, organizations need a structured framework that all teams can follow.
Here’s a simple 3-step Frosty AI Scaling Framework that companies can implement:
Step 1: Establish a Multi-LLM Strategy (Foundational Phase)
🔹 Define when to use different models based on cost, performance, and latency needs.
🔹 Ensure vendor flexibility by integrating multiple AI providers early on.
🔹 Use Frosty AI’s routing engine to keep your AI stack adaptable.
Step 2: Implement Observability & Cost Control (Operational Phase)
🔹 Track AI usage across all teams with real-time monitoring.
🔹 Set up a Cost Based Rule on your router to route tasks to a model based on pricing and usage.
🔹 Set up a Performance Based Rule on your router to route tasks to the best-performing model.
Step 3: Automate & Scale AI Adoption (Enterprise Phase)
🔹 Implement auto-routing to dynamically switch models based on efficiency.
🔹 Enable failover protection, ensuring 100% uptime even if a provider goes down.
🔹 Standardize AI governance across the company, so all teams follow best practices.
🚀 Result? A scalable, cost-efficient, and resilient AI infrastructure that supports multiple teams without chaos.
The Future of AI is Flexible, Cost-Efficient, and Resilient
The AI landscape is changing fast, and companies need a smarter way to manage models.
With Frosty AI, organizations can embrace a multi-LLM strategy, reduce costs, and improve performance—all without being tied to a single provider.
Frosty AI is the missing layer between your AI applications and the evolving LLM ecosystem.
Ready to take control of your AI infrastructure?
➡️ Try Frosty AI today at gofrosty.ai


